Azure
Der Unterschied liegt darin, dass dein AKS-Cluster und der Kubelet (Node-Pool) unterschiedliche Managed Identities haben!
🔹 1. aks.identity[0].principal_id → Cluster-Managed Identity (System-Assigned oder User-Assigned)
Wenn du in Terraform data.azurerm_kubernetes_cluster.aks.identity[0].principal_id nutzt, bekommst du die Managed Identity des AKS-Clusters selbst.
Wann wird diese Identity verwendet?
- Falls dein AKS-Cluster mit einer System-Assigned Identity oder einer User-Assigned Identity erstellt wurde.
- Wird oft für API-Calls oder Berechtigungen auf Subscription-/Resource-Group-Ebene genutzt.
- Diese ID wird genutzt, wenn du z. B. eine Azure Policy oder ein RBAC-Role Assignment für das AKS-Cluster machst.
💡 Beispiel:
data "azurerm_kubernetes_cluster" "aks" {
name = "aks-test"
resource_group_name = "aks-test"
}
output "aks_identity" {
value = data.azurerm_kubernetes_cluster.aks.identity[0].principal_id
}
Dieser Wert entspricht der „principalId“ des AKS-Clusters.
🔹 2. identityProfile.kubeletidentity.clientId → Kubelet-Managed Identity (Node Pool)
Die identityProfile.kubeletidentity.clientId, die du mit az aks show bekommst, gehört zur Kubelet-Managed Identity.
Wann wird diese Identity verwendet?
- Diese Managed Identity wird von den AKS-Knoten (Worker Nodes) genutzt.
- Sie wird verwendet, wenn die Nodes z. B. Azure Container Registry (ACR), Key Vault oder andere Azure-Ressourcen aufrufen.
- Falls du Azure Files oder Azure Disks als Volumes mountest, nutzt der Kubelet-Daemon diese Identity.
💡 Beispiel:
aks show --resource-group aks-test --name aks-test --query "identityProfile.kubeletidentity.clientId" --output tsv
Dieser Wert entspricht der „clientId“ der Kubelet Identity.
🔹 Unterschied in der Praxis
| Identity-Typ | Terraform (azurerm_kubernetes_cluster) | CLI (az aks show) | Verwendung |
|---|---|---|---|
| Cluster-Managed Identity | aks.identity[0].principal_id | identity.principalId | Wird für Azure-Ressourcen-Berechtigungen auf Cluster-Ebene genutzt |
| Kubelet-Managed Identity (Node Pool) | Nicht direkt abrufbar mit Terraform | identityProfile.kubeletidentity.clientId | Wird von Knoten für ACR, Key Vault, Azure Disks etc. genutzt |
🔹 Wie bekomme ich die Kubelet-Identity mit Terraform?
Aktuell bietet Terraform keine direkte Möglichkeit, die kubeletidentity.clientId aus identityProfile abzurufen.
Ein Workaround wäre, das CLI-Kommando mit data "external" oder local-exec auszuführen:
data "external" "kubelet_identity" {
program = ["bash", "-c", "az aks show --resource-group aks-test --name aks-test --query 'identityProfile.kubeletidentity.clientId' --output tsv"]
}
output "kubelet_identity" {
value = data.external.kubelet_identity.result["client_id"]
}
📌 Fazit
aks.identity[0].principal_idist die Managed Identity des Clusters.identityProfile.kubeletidentity.clientIdist die Managed Identity der Worker Nodes (Kubelet).- Terraform kann die Kubelet Identity aktuell nicht direkt abrufen – nur über
az aks show.
Möchtest du noch genauere Details zu deiner AKS-Konfiguration? 😊
4o
Der Unterschied zwischen role_based_access_control und azure_active_directory_role_based_access_control liegt in der Art, wie die Zugriffssteuerung (RBAC) und die Integration von Azure Active Directory (AAD) im Azure Kubernetes Service (AKS) implementiert wird.
1. role_based_access_control
- Dies aktiviert das native Kubernetes RBAC (Role-Based Access Control) innerhalb des AKS-Clusters.
- Die
azure_active_directory-Sektion innerhalb vonrole_based_access_controlermöglicht die Integration von Azure AD in das Kubernetes RBAC-System. - Zugriff wird durch Kubernetes-Rollen und RoleBindings/ClusterRoleBindings gesteuert.
- Hier nutzt du Kubernetes-RBAC in Kombination mit Azure AD für die Authentifizierung.
- Beispiel:
role_based_access_control {
enabled = true
azure_active_directory {
managed = true
admin_group_object_ids = ["<aad-admin-group-object-id>"]
}
}- Wann verwenden?
- Wenn du Kubernetes-native RBAC mit Azure AD verwenden möchtest.
- Für feingranulare Kontrolle auf Kubernetes-Ebene.
2. azure_active_directory_role_based_access_control
- Dies aktiviert Azure RBAC für das AKS-Cluster.
- Azure RBAC nutzt die Azure-Rollen (
Contributor,Reader,Owner) und benutzerdefinierte Azure-Rollen, um Zugriffsrechte direkt in Azure zu steuern, ohne auf Kubernetes-RBAC angewiesen zu sein. - In Kombination mit
azure_rbac_enabled = truewird Azure RBAC die einzige Methode zur Steuerung des Zugriffs. - Beispiel:
azure_active_directory_role_based_access_control {
admin_group_object_ids = var.aks_admin_group_object_ids
azure_rbac_enabled = true
}- Wann verwenden?
- Wenn du Zugriffskontrolle auf Azure-Ebene möchtest, ohne dich mit Kubernetes-RBAC beschäftigen zu müssen.
- Für einfachere und zentralisierte Verwaltung durch Azure-Rollen.
Hauptunterschiede:
| Feature | role_based_access_control | azure_active_directory_role_based_access_control |
|---|---|---|
| Typ der Zugriffssteuerung | Kubernetes RBAC mit Azure AD-Integration | Azure RBAC (Azure-Rollen und -Berechtigungen) |
| Granularität | Sehr fein granular (z. B. Zugriff auf einzelne Namespaces) | Grob granular, basierend auf Azure-Rollen |
| Konfigurationsebene | Innerhalb des Kubernetes-Clusters | Innerhalb von Azure |
| Komplexität der Verwaltung | Erfordert Kubernetes-spezifische Kenntnisse | Einfacher, da Azure RBAC in der Azure-Umgebung bleibt |
| Integration mit bestehenden Systemen | Ideal, wenn du bereits Kubernetes-RBAC verwendest | Ideal, wenn du vorhandene Azure-Rollen und Zugriffssteuerungen nutzt |
Wann solltest du was verwenden?
- Verwende
role_based_access_control, wenn:- Du Kubernetes-native Zugriffssteuerung benötigst.
- Du eine detaillierte, anwendungs- oder namespace-spezifische Steuerung wünschst.
- Verwende
azure_active_directory_role_based_access_control, wenn:- Du eine zentralisierte, einfache Zugriffssteuerung auf Azure-Ebene bevorzugst.
- Du bereits Azure-Rollen und RBAC in deiner Organisation etabliert hast.
Kombination:
Du kannst nicht beide Methoden gleichzeitig aktivieren. Wähle die Methode, die am besten zu deinen Anforderungen passt.
4o
- VNets
- Virtual Networks sind separiert von anderen virtual Networks und können als physical Networks gesehen werden.
- Ressources (VMs, DBs,…) können per default im eigenen VNet communizieren aber nicht in anderen VNets
- VNets sind kostenfrei, aber limitiert bis 50 über alle Regions
- VNets sind nicht Region übergreifend.
- VNets können via „Peering“ verbunden werden
- VNets sind in Subnetze unterteilt (CIDR Notation) max. 65.536 IP Adressen
- VNets sind mit NSG geschützt, die aber den Subnets zugeordnet sind.
- z.B.: 10.0.0.0/16 = 10.0.0.0 – 10.0.255.255 (65.536 addresses)
- Die Azure Firewall kann einem VNet zugewiesen werden (https://learn.microsoft.com/de-de/azure/firewall/overview).
- Always minimize the Access to the Ressources in a VNet
- SubNets
- logisches Segment in einem VNet
- bekommt einen IP Bereich aus dem VNet
- Ressourcen werden in einem Subnet deplyed und nicht direkt im VNet
- Subnetze im selben VNet können untereinander kommunizieren
- Subnetze sind kostenfrei, es gibt ein Limit von 3000
- z.B. : 10.0.0.0 – 10.0.0.255 (/24) (256 addresses)
- Front und Backend Services können in verschiedene Subnetze deployed werden
- Load Balancer
- Application Gateway
- Network Security Group (NSG)
- Filter Regeln (Security Rule) nach SourceIP, SourcePort, DestinationIP, DestinationPort, Protokoll
- Network Peering
- Verbindet zwei VNets
- NSG können angewand werden
- Traffic wird berechnet mit 1ct pro GB (jeweils inbound und outbound)
1. Verschiedene Subnetze im selben VNET
Dies ist die häufigste und empfohlene Praxis in vielen Umgebungen. Die Idee ist, Frontend und Backend in getrennten Subnetzen innerhalb desselben Virtual Network zu platzieren.
Vorteile:
- Segmentierung und Sicherheit: Frontend- und Backend-Services können getrennt werden, und Firewall-Regeln oder NSGs (Network Security Groups) können implementiert werden, um den Zugriff nur auf das Nötigste zu beschränken. Beispielsweise könnte das Backend-Subnetz nur Anfragen vom Frontend akzeptieren und keine direkte Verbindung zum Internet haben.
- Leichtes Routing: Da sich beide Subnetze im selben VNET befinden, ist das Routing zwischen ihnen einfach und performant. Es ist keine zusätzliche Konfiguration für die Kommunikation zwischen den Services nötig.
- Sicherheit auf Layer-3 (Netzwerk): Durch die Trennung in Subnetze können Zugriffskontrollen feiner granuliert werden. Regeln können beispielsweise sicherstellen, dass das Frontend auf das Backend zugreifen kann, aber nicht umgekehrt.
- Kosteneffizienz: Da alles im selben VNET bleibt, gibt es keine zusätzlichen Kosten oder Komplexität für die Verbindung von verschiedenen VNETs (z.B. Peering oder Gateways).
Wann sinnvoll?:
- Wenn beide Services regelmäßig miteinander kommunizieren müssen (z.B. API-Aufrufe des Frontends an das Backend).
- Wenn Sicherheit durch Netzwerksicherheit (Subnetz, Firewalls, NSGs) erreicht werden soll.
- Wenn die Verwaltung einfach bleiben soll und der Overhead einer separaten Netzwerkverwaltung vermieden werden soll.
2. Verschiedene VNETs für Frontend und Backend
In einigen Szenarien kann es sinnvoll sein, Frontend und Backend in verschiedenen Virtual Networks zu deployen. Dies bietet zusätzliche Isolation, kommt aber auch mit mehr Komplexität.
Vorteile:
- Stärkere Isolation: Durch die Verwendung von separaten VNETs können Sie eine noch stärkere Trennung zwischen Frontend und Backend erreichen. Dies ist besonders nützlich, wenn es notwendig ist, die Umgebung stark voneinander zu isolieren (z.B. aus regulatorischen oder Compliance-Gründen).
- Erweiterte Sicherheitskontrollen: Separate VNETs ermöglichen eine noch granularere Kontrolle über die Netzwerkkommunikation. Sie können striktere VNET-Peering-Regeln festlegen oder Gateways zur Kommunikation zwischen VNETs verwenden.
- Multi-Cloud oder Multi-Regionen: Wenn Ihr Frontend in einer anderen Cloud oder einer anderen Region läuft, ist ein separates VNET möglicherweise erforderlich. Das Backend könnte in einer anderen Cloud-Umgebung liegen, um Daten geografisch oder aus Compliance-Gründen zu trennen.
Nachteile:
- Komplexität: Die Verwaltung mehrerer VNETs bringt zusätzliche Komplexität. Sie müssen VNET-Peering oder andere Netzwerktechnologien konfigurieren, um sicherzustellen, dass die beiden Netzwerke miteinander kommunizieren können.
- Kosten: VNET-Peering oder die Verwendung von Gateways (z.B. VPN oder ExpressRoute) zwischen VNETs kann zusätzliche Kosten verursachen.
- Leistungsüberlegungen: Die Latenz kann zunehmen, wenn die Kommunikation zwischen zwei verschiedenen VNETs über ein Gateway oder andere Netzwerkmechanismen erfolgt.
Wann sinnvoll?:
- Wenn Sie eine besonders starke Trennung zwischen Frontend und Backend benötigen (z.B. um strenge Sicherheitsvorgaben zu erfüllen).
- Wenn Ihre Frontend- und Backend-Services in unterschiedlichen Regionen oder Cloud-Providern betrieben werden.
- Wenn Sie eine hoch skalierbare Multi-Tenant-Architektur haben, bei der jeder Teil einer Anwendung in einer eigenen isolierten Umgebung liegt.
Zusammenfassung:
- Verschiedene Subnetze innerhalb desselben VNET:
- Die bevorzugte Lösung für die meisten Anwendungsfälle.
- Einfaches Routing, hohe Effizienz und ausreichende Sicherheit.
- Ideal, wenn Frontend und Backend regelmäßig miteinander kommunizieren müssen.
- Verschiedene VNETs:
- Mehr Isolation und Sicherheit, aber komplexer und kostspieliger.
- Sinnvoll, wenn besonders hohe Sicherheitsanforderungen bestehen oder wenn die Systeme stark voneinander getrennt sein müssen (z.B. aus Compliance-Gründen oder in Multi-Region-Szenarien).
In den meisten Fällen ist es effizienter und einfacher, Frontend- und Backend-Services in getrennte Subnetze innerhalb desselben VNET zu deployen. Separate VNETs sind eher in speziellen Szenarien mit besonderen Anforderungen erforderlich.
! Spot node pool can’t be a default node pool, it can only be used as a secondary pool.
Hier der default Node Pool:
resource "azurerm_kubernetes_cluster" "aks" {
name = "aks-demo-cluster"
location = azurerm_resource_group.aks_rg.location
resource_group_name = azurerm_resource_group.aks_rg.name
dns_prefix = "aksdemocluster"
default_node_pool {
name = "default"
node_count = 1
vm_size = "Standard_DS2_v2"
}
identity {
type = "SystemAssigned"
}
network_profile {
network_plugin = "azure"
load_balancer_sku = "Standard"
}
tags = {
environment = "Demo"
}
}Hier ein Spot Node Pool:
resource "azurerm_kubernetes_cluster_node_pool" "spot_pool" {
name = "spotpool"
kubernetes_cluster_id = azurerm_kubernetes_cluster.aks.id
vm_size = "Standard_DS2_v2"
node_count = 1
enable_auto_scaling = true
min_count = 1
max_count = 3
priority = "Spot"
eviction_policy = "Delete"
spot_max_price = -1 # Nutzt den aktuellen Spot-Preis
tags = {
environment = "Spot"
}
}Erklärung:
default_node_pool: Ein minimaler Node Pool, der verwendet wird, um das Cluster initial zu erstellen.azurerm_kubernetes_cluster_node_pool: Hier wird ein zusätzlicher Node Pool erstellt, der Spot-Instanzen und Autoscaling unterstützt. Dieser Pool wird mit dem Haupt-Cluster verbunden.
Wichtige Hinweise:
- Autoscaling und Spot-Instanzen müssen in separaten Node Pools konfiguriert werden.
- Wenn du einen Spot-Node Pool nutzt, ist es eine gute Praxis, immer einen regulären Node Pool (wie
default_node_pool) zu behalten, da Spot-Instanzen potenziell jederzeit entfernt werden können.
Test Framework installieren
dotnet add package xunit
dotnet add package xunit.runner.visualstudio
dotnet add package Microsoft.NET.Test.SdkVisual Studio Code Extension
Es gibt eine Extension für .NET Tests in Visual Studio Code:
- Installiere die .NET Core Test Explorer Extension: Sie ermöglicht es dir, Tests direkt aus VS Code auszuführen und die Ergebnisse anzuzeigen.
Um die Erweiterung zu installieren:
- Gehe in VS Code zu den Extensions (Ctrl+Shift+X) und suche nach .NET Core Test Explorer. Installiere sie.
Anlegen der Webapp und der Test Unit
dotnet new webapp -n WebAppDemo -o WebAppDemo
dotnet new xunit -n WebAppTest -o WebAppTestVerlinken der Test Unit zur Webapp
cd WebAppTest
dotnet add reference ../WebAppDemo/WebAppDemo.csprojmssql extension installieren
dotnet add WebAppDemo package Microsoft.EntityFrameworkCore.SqlServerIn Visual Studio Code bei den Erweiterungen nach „mssql“ suchen
Optional: lokal einen mssql docker Container ausführen (linux)
docker run -e "ACCEPT_EULA=Y" -e "MSSQL_SA_PASSWORD=xxxx" \
-p 1433:1433 --name localhost --hostname localhost -d \
mcr.microsoft.com/mssql/server:2022-latest- Einloggen bei https://dev.azure.com/
- Neues Projekt anlegen
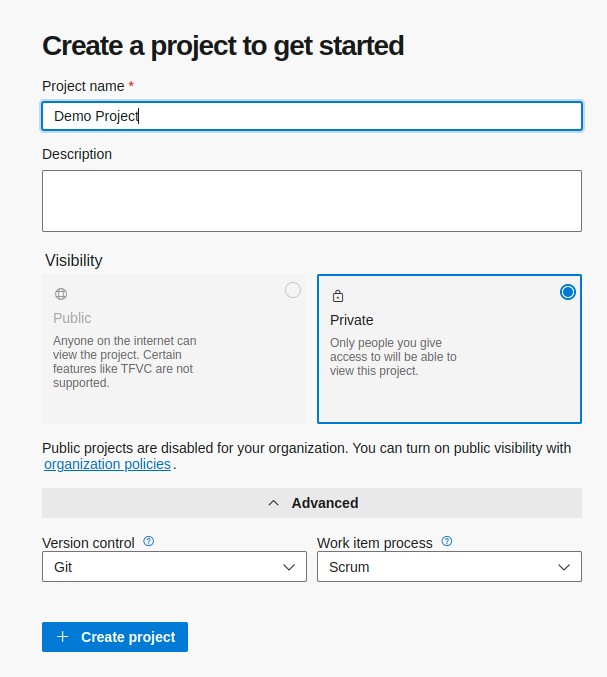
Unter WorkItems ein Epic anlegen
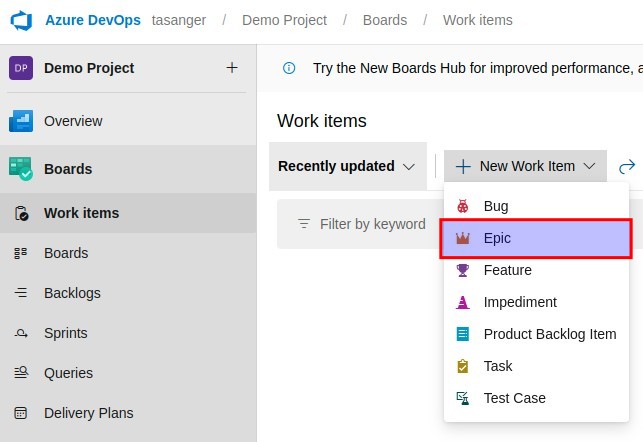
Unter WorkItems ein Feature anlegen
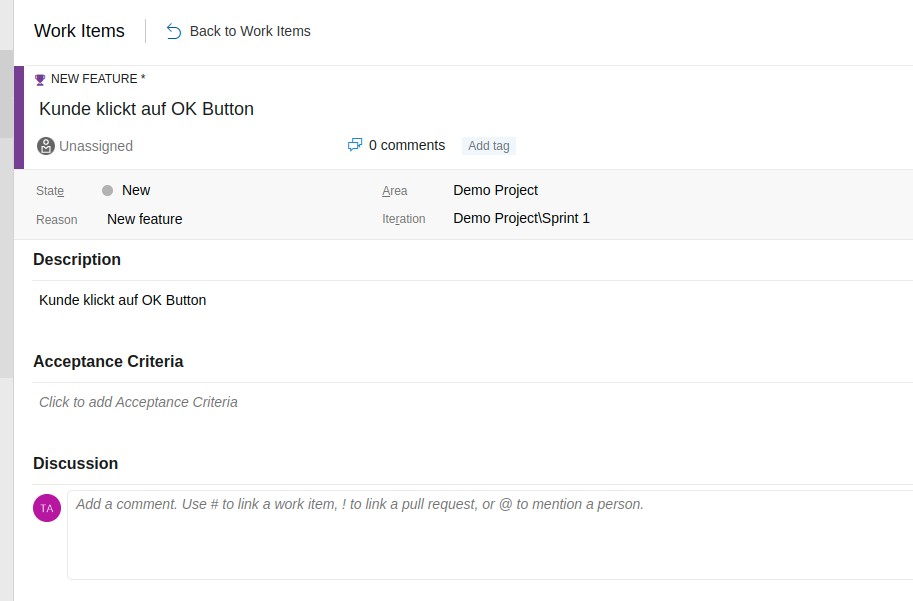
Unter dem angelegten Epic das Feature verknüpfen (Add Link/Existing Item)
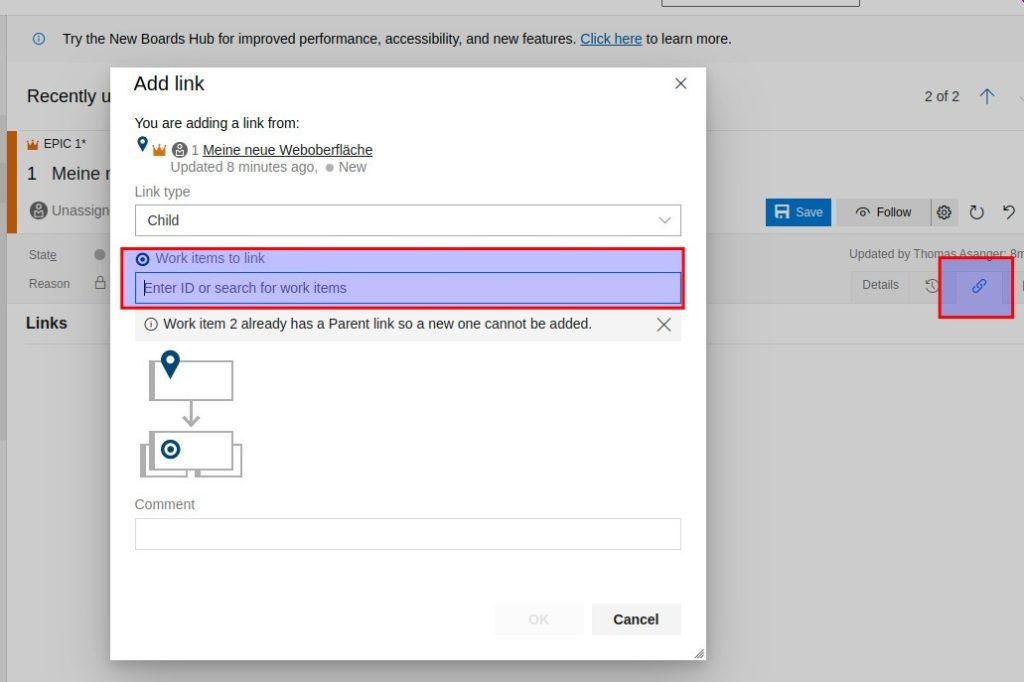
Ein PBI (Produkt Backup Item anlegen) und drauf klicken um eine Userstory zu hinterlegen
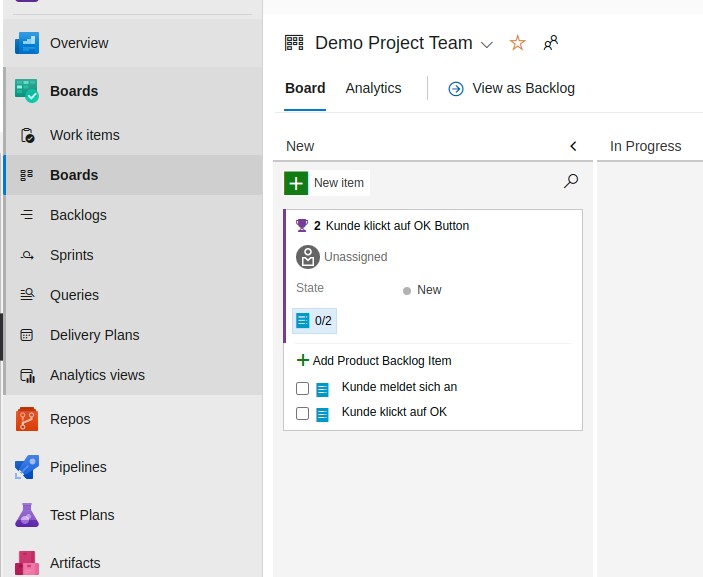
Die Backlog Items sortieren (Drag and Drop) und zur Board Ansicht wechseln
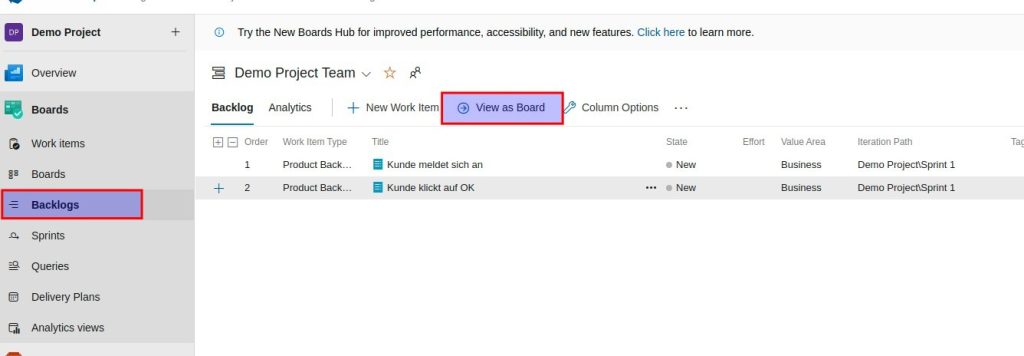
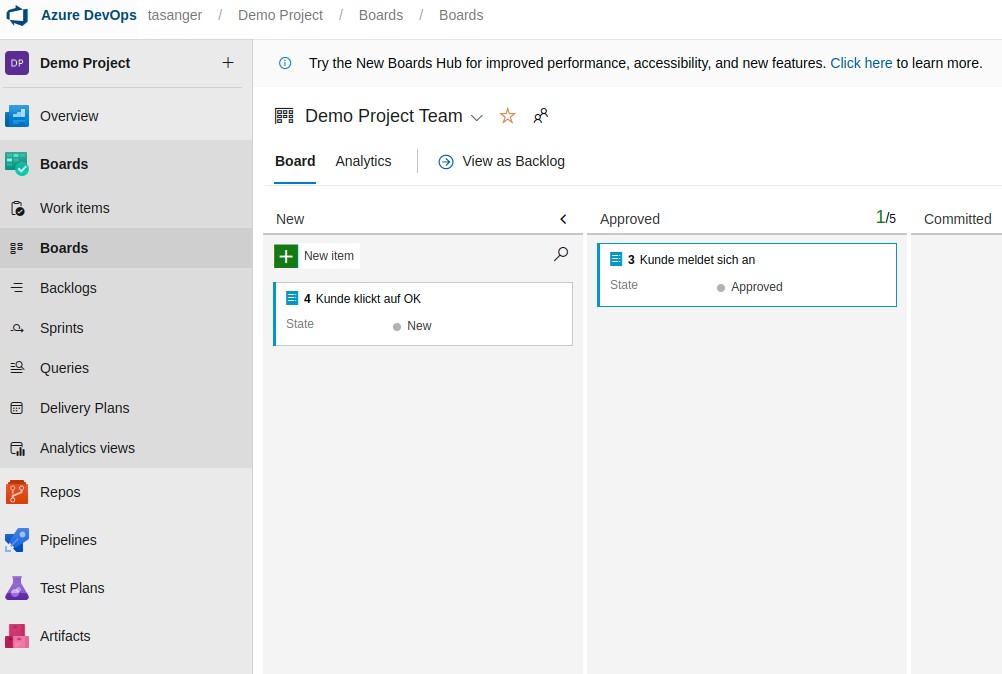
Product Owner muss die PBIs approven (in Spalte verschieben oder auf State klicken und approved wählen )
Unter Project Settings die Sprints konfigurieren
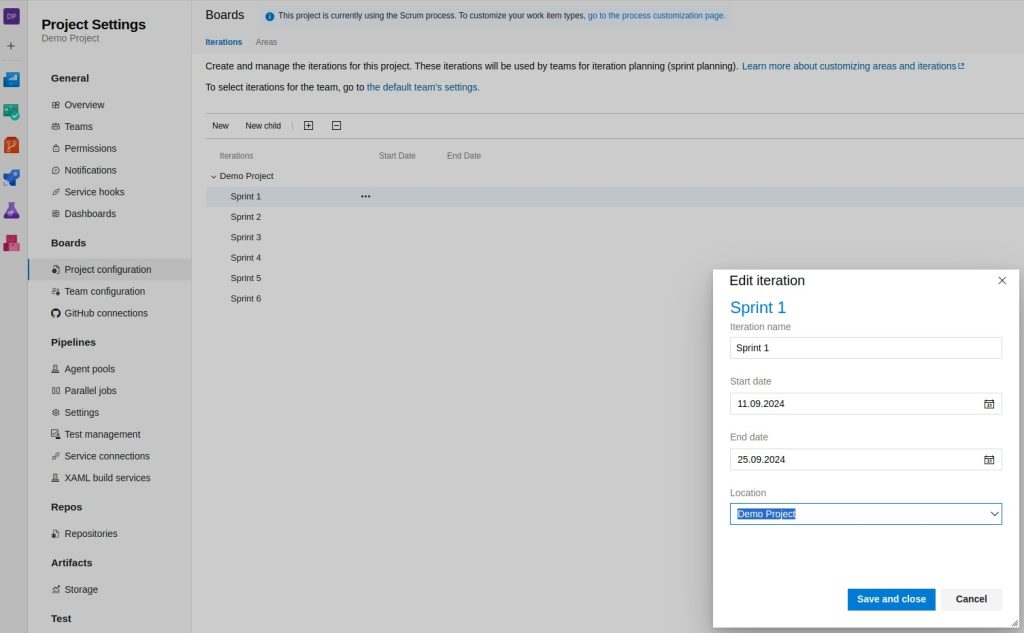
Hier können per Drag and Drop die PBI den Sprints zugewiesen werden.
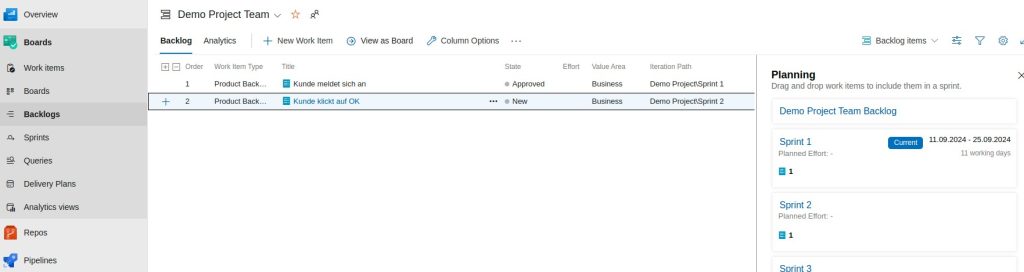
Hier können Tasks für die PBI erstellt werden(Sprints -> Taskboard)